
|
| |
|
Слаботочка Книги 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [27] 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 осуществляться относительно грубое квантование. Таким образом, спектр шума квантования подгоняется под мгновенный спектр сигнала. В смысле восприятия речи это свойство является весьма желательным, так как позволяет речевому сигналу маскировать шум квантования. (Человеческое ухо воспринимает речь, измеряя уровень мгновенной энергии в отдельных частотных полосах. Отсюда относительно низкий уровень шумов в полосе, не содержащей энергии речи, воспринимается в большей степени, чем больший уровень шума в полосе со значительной энергией речи.) Вторым достоинством кодирования с разделением на полосы является то, что скорость передачи (качество) для каждой из полос может быть оптимизирована в соответствии со степенью воздействия каждой отдельной полосы на восприятие. В частности, относительно большое число разрядов на дискрет может быть использовано для низких частот, где это важно для сохранения основного тона и структуры формант гласных и звонких согласных звуков. На высоких частотах, однако, можно использовать меньшее число разрядов на дискрет, поскольку шумоподобные глухие звуки не требуют сопоставимого качества воспроизведения. Как сообщалось в [7], кодеры с разделением на полосы обеспечивают значительное уменьшение скорости передачи по сравнению с более общими и простыми алгоритмами кодирования: адаптивными ДМ и ДИКМ. В частности, сообщается, что для кодеров с разделением на полосы и скоростью передачи 16 кбит/с восприятие речи эквивалентно восприятию для ДИКМ-кодеров с адаптацией и скоростью передачи 22 кбит/с. Сообщается также, что кодер с разделением на полосы и скоростью передачи 9,6 кбит/с эквивалентен ДМ-кодеру с адаптацией и скоростью передачи 19,5 кбит/с. С подробным описанием и анализом характеристик кодирования с разделением на полосы можно ознакомиться в [33]. 3.8. ВОКОДЕРЫ По большей части алгоритмы кодирования (декодирования), описанные выше, предназначены в первую очередь для воспроизведения формы входного сигнала с максимально возможной точностью. Таким образом, они предполагают малую степень или полное отсутствие знаний о природе сигнала, который они обрабатывают, и придожимы, по существу, к любому сигналу, попадающему в канал ТЧ. Исключения возникают с тех случаях, когда кодирование с разделением на полосы или с адаптивным предсказанием рассчитано на получение низких скоростей передачи (20 кбит/с или менее). На таких скоростях передачи в кодерах должна быть точно учтена статистика речевого сигнала и они не могут обеспечить эквивалентное качество для других сигналов. Дифференциальные системы, такие, в которых используются ДИКМ и дельта-модуляция, также обладают определенными свойствами, специализированными для передачи речи, из-за их недостатков, связанных с кодированием высоких частот (перегрузка по крутизне). Процедуры преобразования в цифровую форму, описанные в этом разделе, весьма специфически кодируют речевые сигналы и причем только речевые сигналы. По этой причине все устройства, реализующие такие методы, носят название вокодеры , полученное путем соединения слов voice coders . Поскольку эти способы рассчитаны специально на речевые сигналы, они не могут быть применены в телефонной сети общего пользования, в которой должна быть обеспечена передача и других аналоговых сигналов (таких, как сигналы модемов). Кроме того, вокодеры обычно создают ненатуральное, или синтетическое звучание речи. Основным назначением вокодера является кодирование только важных для восприятия параметров речи с уменьшенным числом символов по сравнению с их числом в более общих кодерах формы сигнала. Благодаря этому они могут быть использованы для передачи в ограниченной полосе частот, чего не могут дать другие способы. Некоторые из основных применений вокодеров следующие: записанные сообщения (например, набран неправильный номер ), передача засекреченного речевого сигнала по аналоговым каналам ТЧ, формирование речевого сигнала на выходе ЭВМ и образовательные игры. Недавно возникло особенно интересное применение одного из типов вокодера (с линейным предсказанием) для реализации нескольких речевых каналов на одной арендованной линии, обеспечивающей передачу ТЧ. При использовании арендованной линии высокого качества для передачи сигнала со скоростью 9600 бит/с можно по одной такой линии передать четыре речевых сигнала со скоростью 2400 бит/с, объединив их путем временного группообразования. В этом случае, следовательно, переход к цифровой форме фактически уменьшает полосу речевого сигнала. Хотя эти системы воспроизводят разборчивую речь, ее общее качество ниже телефонных стандартов. В этом разделе описываются три самых основных способа вокодерного преобразования: с помощью канального вокодера, фор-мантного вокодера и кодера с линейным предсказанием. Предложено и изучено множество других форм и вариантов вокодеров. Для рассмотрения некоторых из них и ознакомления с расширенной библиографией по данному предмету можно обратиться к [7]. Основное требование для обеспечения хорошего качества речи состоит в сохранении кратковременного энергетического спектра сигнала. Фазовые соотношения между отдельными частотными составляющими намного менее существенны для восприятия. Один из лучших примеров нечувствительности уха к фазе демонстрируется во время исполнения на пианино двух нот одновременно или почти одновременно. Общий звук воспринимается слушателем как тот же самый, если одна нота прозвучала чуть позже другой. По существу, ухо воспринимает уровень энергии на различных частотах в спектре речи, но не фазовые соотношения между отдельными частотными составляющими. Что означает кодеры речевого сигнала .- Прим. перев. sin wt + sin 2 sin 0}t + sin(2wf + Рис. 3.40. Эффект сдвига фаз при сложении двух синусоидальных колебаний Эффект сдвига фазы одной из компонент составного сигнала показан на рис. 3.40. Первый составной сигнал получен, когда две отдельные частотные компоненты имеют идентичные начальные фазы. Второй составной сигнал соответствует случаю, когда две частотные составляющие имеют начальные фазы, сдвинутые друг относительно друга на 90°. Отметим, что составные сигналы заметно различаются, хотя ухом разница не воспринимается. По этим причинам временная форма сигнала, воспроизводимая вокодером, как правило, имеет лишь небольшое сходство с исходной формой входного сигнала. 3.8.1. Канальный вокодер Канальные вокодеры были впервые разработаны в 1928 г. Г. Дад-ли [34]. В первом варианте, выполненном Дадли, речевой сигнал путем компрессирования преобразовывался в аналоговый сигнал с общей полосой порядка 300 Гц. Были разработаны цифровые канальные вокодеры, основанные на этих идеях и работающие в диапазоне от 1 до 2 кбит/с. Основная часть процесса кодирования в канальном вокодере состоит в определении кратковременного спектра сигнала. Как показано на рис. 3.41, блок из полосовых фильтров используется для разделения энергии речи на полосы, в которых производится двух-полупериодное выпрямление и фильтрация для определения относительных уровней мощности. Отдельные уровни мощности кодируются и передаются на приемную сторону. Отметим, что этим канальный вокодер весьма похож на кодер с разделением на полосы, рассмотренный ранее. В кодере с разделением на полосы, однако, обычно используются полосовые фильтры с более широкими полосами, что заставляет чаще осуществлять дискретизацию сигналов на выходах полосовых фильтров (определяется форма сигнала, а не уровень мощности). Поскольку кодер с разделением на полосы кодирует форму сигнала, он передает также и информацию о фазе, на которую в канальном вокодере не обращают внимания. В дополнение к измерению спектра сигнала современные канальные вокодеры определяют также характер возбуждения речи (гласный или звонкий согласный звук в отличие от глухого звука) и частоту основного тона для гласных или звонких согласных звуков. 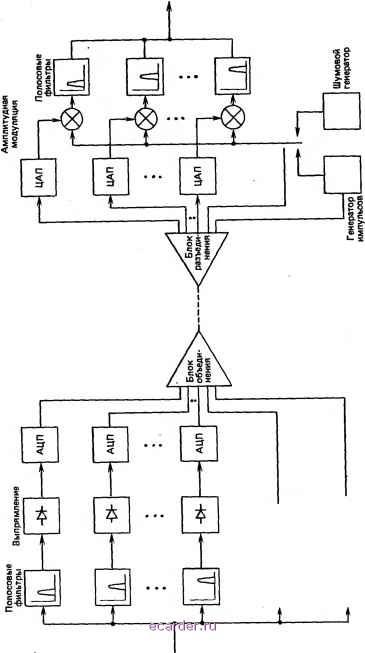 в; а X
Измерения возбуждения используются для синтеза речевого сигнала в декодере путем пропускания сигнала соответственно подобранного источника через модель функции передачи речеобразующего тракта в частотной области. Возбуждение гласных или звонких согласных звуков имитируется с помощью генератора импульсов с частотой повторения, определяемой периодом основного тона. Возбуждение глухих звуков имитируется шумовым генератором. Вследствие синтезируемого характера возбуждения этот тип вокодера иногда называют вокодером с возбуждением основного тона. Как показано на рис. 3.41, декодер реализует функцию речеобразующего тракта с помощью блока полосовых фильтров, уровни мощности на входах которых определяются уровнями мощности в соответствующих полосах кодера. Таким образом, выходные сигналы каждого полосового фильтра в декодере аналогичны выходным сигналам соответствующих полосовых фильтров в кодере. Суперпозиция сигналов отдельных полос воссоздает спектр исходного сигнала. Было разработано множество вариантов типового канального вокодера, определяемых характером возбуждения и средствами кодирования уровней мощности. Недавние успехи в цифровой технике привели к использованию для определения спектра входного сигнала цифровой обработки с помощью алгоритмов преобразования Фурье вместо блока аналоговых фильтров. Все виды вокодеров, которые измеряют энергетический спектр, называются иногда спектральными канальными вокодерами , чтобы отличить их от вокодеров во временной области, таких как кодеры с линейным предсказанием, рассматриваемые ниже. Наиболее трудный аспект реализации большинства вокодеров связан с определением основного тона гласных или звонких согласных звуков. Кроме того, определенные звуки затруднительно четко определить как чисто звонкие или чисто глухие. Вследствие этого желательное усовершенствование типового вокодера связано с получением более точных характеристик возбуждения. Без точной информации о возбуждении качество речи на выходе вокодера является совершенно неудовлетворительным и часто зависит как от говорящего, так и от конкретных произнесенных звуков. Некоторые из более совершенных вокодеров при скорости передачи 2400 бит/с создают в высшей степени разборчивую речь, хотя и с несколько синтетическим звучанием [19]. 3.8.2. Формантный вокодер Как показано в спектрограмме на рис. 3.25, мгновенный энергетический спектр речи редко занимает сразу всю полосу ТЧ (от 200 до 3400 Гц). Энергия речи имеет тенденцию концентрироваться в трех или четырех пиках, называемых формантами. Формантный вокодер определяет положение и амплитуду этих спектральных пиков и передает эту информацию вместо огибающей всего спектра. Вследствие этого формантный вокодер формирует цифровой сигнал с пониженной скоростью передачи за счет кодирования только наиболее значительных мгновенных составляющих в спектре речи. Самым важным требованием для получения приемлемой речи при использовании формантного вокодера является точное прослеживание изменений в формантах. Если это выполняется, формантный вокодер может дать разборчивую речь при скорости передачи менее 1000 бит/с. 3.8.3. Кодирование с линейным предсказанием Кодер с линейным предсказанием (КЛП) является распростра-неннцм типом вокодера, который извлекает существенные для восприятия характеристики речи непосредственно из временной формы сигнала, а не из частотного спектра, как в канальном и формантном вокодерах. По существу, КЛП анализирует речевой сигнал для получения меняющейся во времени модели возбуждения речеобразующего тракта и функции передачи. Синтезатор в приемном полукомплекте воссоздает речевой сигнал путем пропускания полученного возбуждения через устройство, соответствующее математической модели речеобразующего тракта. Синтезатор приспосабливается к изменениям параметров модели и элементов возбуждения путем периодического уточнения этих параметров. Однако предполагается, что в течение любого одного интервала уточнения речеобразующий тракт представляет собой линейное устройство с постоянными во времени параметрами. Структурная схема типовой модели для генерации речи представлена на рис. 3.42. Таким образом, рис. 3.42 отображает также и модель работающего по принципу линейного предсказания декодера (синтезатора). Выражение, описывающее работу модели речеобразующего тракта, показанного на рис. 3.42, имеет вид у(п)= 2 a,y(n-k)+Gx(n), (3.17) где у(п) - п-й дискрет на выходе; - к-к коэффициент предсказания; G - коэффициент усиления; х(п) - входной сигнал в момент дискретизации п; р - порядок модели. Отметим, что выходной речевой сигнал в формуле (3.17) представлен в виде суммы входного сигнала в настоящий момент и линейной комбинации р предыдущих выходных сигналов речеобразующего тракта. Эта модель является адаптивной в том смысле, что в кодере периодически определяется новое семейство коэффициентов предсказания, соответствующих последовательным отрезкам речи. В этом кодирование с линейным предсказанием аналогично адаптивной ДИКМ или кодированию с адаптивным предсказанием. Основное отличие, однако, состоит в методе определения коэффициентов предсказания и в том, что в КЛП не измеряются и не кодируются разностные сигналы, или сигналы ошибки. Вместо этого при определении коэффициентов предсказания минимизируются средние квадратические значения ошибок. Возможность избежать 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [27] 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |